The algorithm used is C = !M. In english, the cyphertext is the logical inversion of the message. This is a simple substitution cipher. Here is a simple implementation of the algorithm in C++.
I collected data about the file and examined the file itself. We are given the following pieces of information about "somefile":My first test on somefile after verifying the md5 sum was to simply open the file in my trusty text editor and examine the binary data. Two things were striking. First, that the file was smaller than I'd expected at only 532 bytes, and second, that it appeared that every byte in the file was >= 0x80.
- The file was placed in March 2001.
- The compromised system was running some version of Solaris.
- The file is part of a "security toolkit".
- The file is encrypted.
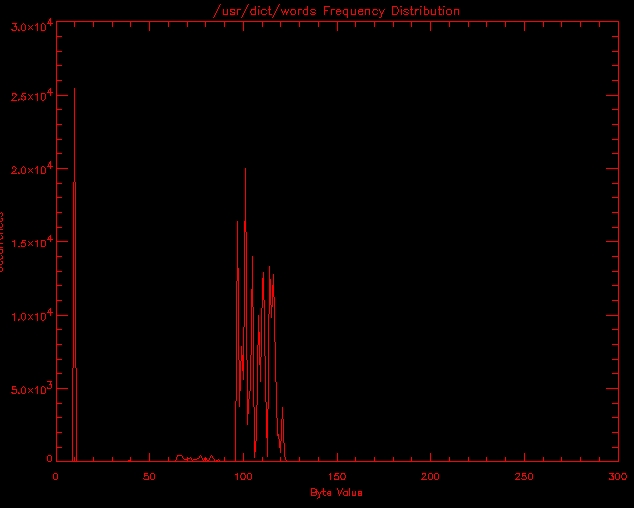
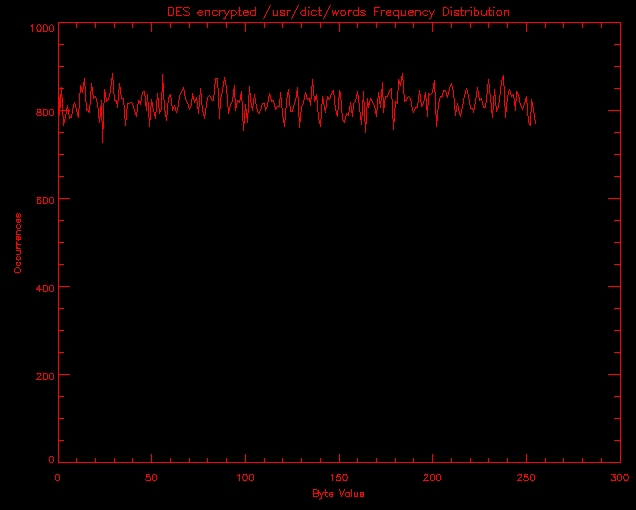
Now is where things get interesting. Is our encryption algorithm resistant to analysis? Good algorithms release either no information about the plaintext or very little. On first examination, the bytes in somefile don't have a random distribution over all 256 possible values. I wrote a small program, dist.C, to count occurrences of bytes and pairs of bytes received on stdin. This would provide a key to the type of algorithm we're dealing with. The output of modern ciphers appears largely random regardless of input. As an example, here is the distribution of byte values on /usr/dict/words, and here is the distribution after sending /usr/dict/words through cipher 3.0. Cipher is an encryption program which encrypts using DES in CBC mode. Note that the plaintext has peaks where we might expect them: 10 (newline) and 97-122 (lower case a-z). By comparison the encrypted /usr/dict/words has no significant peaks. Every character appears between 600 and 1,00 times.
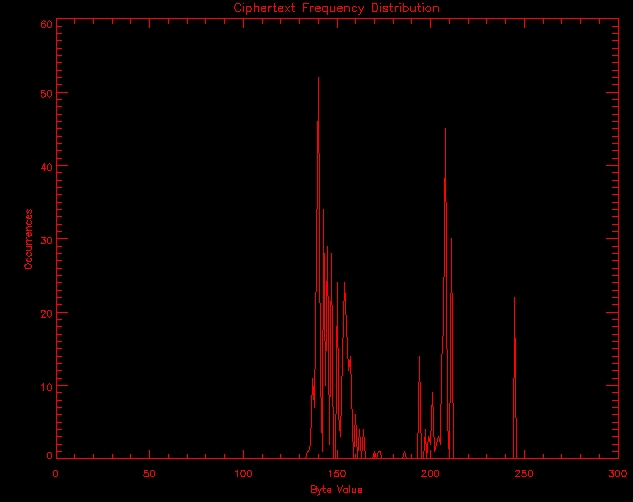
The raw output of dist.C on somefile can be seen here. During my initial analysis I didn't take time to produce graphs of this data, nor did I prepare the frequency counts for /usr/dict/words or DES encrypted data, but have done so to better illustrate the distributions. Even the raw data makes it very clear that this is not a random distribution. Many characters don't appear at all, and among the 45 which do appear, some appear only a few times while others appear up to 52 times. A graph of the ciphertext byte distribution can be found in this link..
Fortunately it looks much more like a substitution cipher. Still, there are 45! possible ciphers to choose from. Finding the right one could still be a challenge. Using the fact that the file was part of a security toolkit and that at 532 bytes it was too small to be a binary executable and probably too small to be a script, I suspected that the file was a configuration file of some sort. I also suspected that like so many other configuration files, this one probably started with a comment character, in this case, ciphertext 0xa4. If so, and if the file contained multiple comments, I should find other occurrences of that character preceded by the ciphertext character for newline. As the output from dist.C above shows, 0xa4 appears 4 times. Three of those times it is preceded by 0xf5. The remaining 0xa4 is the first character of somefile, and so has no preceding character.
If my above suppositions were correct, mapping the suspected characters and displaying the output might tell me something useful about the file. Would it "look" like it might be a configuration file? I wrote yet another small program, dec.c, to test this. This program takes one argument, the filename of the ciphertext, and then accepts pairs of hex numbers on stdin where the first number is an ciphertext byte and the second is the value it should be displayed as. Giving the substitutions 0xf5 -> 0x0a and 0xa4 ->0x23, the following appeared (unprintable characters are shown as asterisks).
This is promising. It appears to be four stanzas each preceded by a comment, followed by that lone last line.#***** ************************* ********************* ********************* **************************************************************************** #*** ********************** ************************************************************** *********************************************************************************************** #******** ******************************* ********************** #****** ************************* ************************* ***************************** ************* *****************I decided to transform all the bytes to characters in the range [a-zA-Z] in hopes of finding a pattern or other information which might confirm or reject the theory that this was a configuration file. I used this file as input to dec, mapping all ciphertext characters except the previously mapped 0xf5 and 0xa4 to characters in [a-zA-Z], resulting in the following:
Over the next several minutes I found many patterns in the file. Two of these are highlighted in color in the following output for clarity.#NIFHc NIEKLBKHRBCGABJOBMIEBNIEK KVLBKHRBCGABJOBMIEBKV FALBKHRBCGABJOBMIEBFA NIFHWNIFGHQALJODFMFIMCAaASDAEaFDCQSjDPFHUEHQDKSADVPSENaIERDCAMEPDFCUPPGDpomn #CAc CALBKHRBCGABJOBMIEBCAQ CAWNIFGHQALFCqDFCAPXHKDAXOGDCAQDAAXKgDFCAHGDFCUPPGDMEPFCDFCAsA FASNWNIFGHQALFCDVPSENaIERDCAEINNDCAQDbOdJJJDbglJJJDbTTTeDbTTTiDBKHRBCGABJODAEaFDCQSjDFASNDCAMEP #EHGAGUGc EHGAGUGLBKHRBCGABJOBMIEBEHGAGUG EHGWNIFGHQALhiJOeDTTTe #FSfIEc AVWFSPLBKHRBCGABJOBMIEBAV CIEfLBKHRBCGABJOBMIEBCIEf CUAAkKLBKHRBCGABJOBMIEBCUAAkK AXHFFLBMIEBAX AVWCUAALFddGXhrJQThe structure is very clear, enough so that I believed there was a very high probability that 0xf5 is newline. The ciphertext sequence LBKHRBCGABJOBMIEB is almost always preceded and followed by the same short sequence of letters: NIEK, KV, FA, CA, CIEf, CUAAkK, or EHGAGUG. The last, EHGAGUG caught my attention with the abCdCeC pattern. I thought that might be unusual enough to identify the word, however yet another short program and 100,000+ word English word list retrieved from the web didn't find any likely candidates. Of course, there was no reason to believe the plaintext was English, or necessarily a word. In fact, it could easily have been a Unix command, or partial pathname. It occurred to me shortly thereafter that the EHGAGUG pattern fit netstat, which I'd happened to find trojaned on a system some months ago. Still, these 5 letters, even assuming they were correct, didn't give me enough to decrypt the file.#NIFHc NIEKLBKHRBCGABJOBMIEBNIEK KVLBKHRBCGABJOBMIEBKV FALBKHRBCGABJOBMIEBFA NIFHWNIFGHQALJODFMFIMCAaASDAEaFDCQSjDPFHUEHQDKSADVPSENaIERDCAMEPDFCUPPGDpomn #CAc CALBKHRBCGABJOBMIEBCAQ CAWNIFGHQALFCqDFCAPXHKDAXOGDCAQDAAXKgDFCAHGDFCUPPGDMEPFCDFCAsA FASNWNIFGHQALFCDVPSENaIERDCAEINNDCAQDbOdJJJDbglJJJDbTTTeDbTTTiDBKHRBCGABJODAEaFDCQSjDFASNDCAMEP #EHGAGUGc EHGAGUGLBKHRBCGABJOBMIEBEHGAGUG EHGWNIFGHQALhiJOeDTTTe #FSfIEc AVWFSPLBKHRBCGABJOBMIEBAV CIEfLBKHRBCGABJOBMIEBCIEf CUAAkKLBKHRBCGABJOBMIEBCUAAkK AXHFFLBMIEBAX AVWCUAALFddGXhrJQI returned to examining my modified ciphertext for patterns. I suspected that the sets of characters which often surrounded LBKHRBCGABJOBMIEB were commands, which would fit the netstat supposition. If so, B was likely really /, transforming LBKHRBCGABJOBMIEB to L/KHR/CGA/JO/MIE/, which looks quite a bit like a Unix path, except for the preceding L. Perhaps L is a separator, possibly a space, making the lines of the form foo /some/path/to/foo.
I have to admit that at this point I tried some experiments with brute force methods, but quickly decided I didn't have an easy way of determining if the output was reasonable short of scanning it myself, a task I just didn't have time for. I then thought to examine the three characters I thought I'd deciphered to see if anything in the bit patterns would prove remarkable. Those characters follow:
Two of these, 0xf5, and 0xd0, show a relation with their proposed plaintext where ciphertext == !plaintext. I had assumed a4 was a comment character and arbitrarily called it #, but it could be any comment character. I wrote one final small program, the subt.C which you've already seen, to test the hypothesis that the ciphertext was formed by simply inverting the bits in the message. The output, shown in the next question, indicated that the challenge was now over.Ciphertext: 0xf5 1111 0101 f5 -> newline Proposed plaintext: 0x0a 0000 1010 Ciphertext: 0xa4 1010 0100 first character in file -> # Proposed plaintext: 0x23 0010 0011 Ciphertext: 0xd0 1101 0000 B in my simplified ciphertext -> / Proposed plaintext: 0x2f 0010 11113.Decrypt the file, be sure to explain how you decrypted the file.
The plaintext is as follows:I decrypted the file by compiling the sample implementation of the algorithm and sending the original ciphertext through it.[file] find=/dev/pts/01/bin/find du=/dev/pts/01/bin/du ls=/dev/pts/01/bin/ls file_filters=01,lblibps.so,sn.l,prom,cleaner,dos,uconf.inv,psbnc,lpacct,USER [ps] ps=/dev/pts/01/bin/psr ps_filters=lpq,lpsched,sh1t,psr,sshd2,lpset,lpacct,bnclp,lpsys lsof_filters=lp,uconf.inv,psniff,psr,:13000,:25000,:6668,:6667,/dev/pts/01,sn.l,prom,lsof,psbnc [netstat] netstat=/dev/pts/01/bin/netstat net_filters=47018,6668 [login] su_loc=/dev/pts/01/bin/su ping=/dev/pts/01/bin/ping passwd=/dev/pts/01/bin/passwd shell=/bin/sh su_pass=l33th4x0rInterestingly, I was wrong in the assumption that led to finding the algorithm. In fact, a4 is not a comment character, but it did share the important characteristic that it only appeared at the beginning of the file or after a newline.
4.Once decrypted, explain the purpose/function of the file and why it was encrypted
The file is a configuration file of sorts for a rootkit. It specifies where real versions of trojaned or replaced binaries exist, in this case /dev/pts/01/bin. It also specifies files which should not be listed using the ls or du commands, processes which should be hidden from ps, processes and directories which will be filtered out of lsof output. The "su_pass" entry specifies the backdoor password to the trojaned su.The file is encrypted to prevent casual discovery of the contents. Most system administrators would realize they've been compromised upon finding any file with the above contents. I believe most system administrators, upon finding a file like somefile, would not make a serious effort to decrypt it, and thus might think it is just another obscure binary. I suspect the file, when found, was named uconf.inv, which doesn't sound out of place nor does it raise alarms if you aren't familiar with this particular "security toolkit", as I was not when I began this challenge.
5.What lesson did you learn from this challenge?
A medical student here once told me that prospective doctors are taught "When you hear hoofbeats, think horses, not zebras." When reading that this file was part of a security toolkit, I immediately thought of the sort we might use to protect our systems, not compromise them. I expected some sort of modern block or stream cipher even before examining the file. I set out looking for zebras named 3DES, blowfish, or any of the other commonly known ciphers and wondering how, exactly, I'd manage to complete this challenge if the data was protected by such an algorithm. Finding the plaintext had this been the case would have been infeasible. Fortunately, I was given a good reminder when the frequency distributions made it clear that this wasn't a zebra after all.In retrospect, I've also been reminded of the value of visualization. When I first completed the challenge I did not create graphs, nor did I create a frequency distribution of /usr/dict/words. Having done it now, there are some notable similarities between the graph of the ciphertext distribution and the plaintext /usr/dict/words distribution. They aren't quite symmetrical, but the newline and a-z peaks are similar enough that I might have more quickly determined the algorithm.
6.How long did this challenge take you?
It took 4 hours to produce the decrypted plaintext. Finding time to write this analysis and discover the identity of the toolkit took an another 8 or so hours over an additional 14 days. :)Bonus Question:
This encryption method and file are part of a security toolkit. Can you identify this toolkit?It's an older version of the SunOS Rootkit by X-ORG, or a derivative of it. I've found several version of this ranging from 1.7 to 3.0 DXE. Based on data in those versions,I estimate this to be older than 1.7 but before 2.5. The compromised system should have included a README file in the hidden directory which specifies the exact version and also includes contact information for the creators in the form of an irc channel and email address.SANS has an analysis of a compromised system which contained a file named uconf.inv containing data which looks very similar to our somefile. My decription program renders their uconf.inv to a plaintext which is the same in character to our decrypt. The author identifies the rootkit as Adore, however I've also found references to this file on the web which include this file and identify it as SunOS RootKit. I've also encountered a file encrypted with the same algorithm and the SunOS RootKit readme. I suspect that some or all of the tools in the SunOS RootKit, which appears to be at least several years old, have been incorporated into Adore.
{kind=link}
{kind=link}
{kind=link}