
Chris Ren
This document is intended to describe our analysis process. We'll cover the tools and techniques we used for different purposes during the reverse engineering process. For detailed description of the capabilities of the target binary, see here. Our reverse engineering process consists of two phases, static analysis and dynamic analysis. Static analysis is a process to comprehend a target binary by examining the binary itself, without its actual interactions with any environment. Dynamic analysis is a process to actually execute a target binary in a controlled environment. During dynamic analysis, by examining the running process' internal states and observing its interactions with the underlying system, one can not only verify the conclusions drawn in the phase of static analysis, but also be able to discover new features previously omitted. We will show you some surprises as well.
Static analysis could be as simple as running the 'strings' utility program on a target binary, and it could be as complicated as generating pseudo C code to study a certain algorithm in the binary. In this section, we'll describe some tools and techniques we used while analyzing the binary statically.
Knowing nothing about the binary, we first ran the 'strings' utility program on the binary.
Interesting strings in the output included:
"@(#) The Linux C library 5.3.12"
This tells us the target system of the binary.
"resolv+: search order not specified or unrecognized keyword, host resolution will fail."
This looks like a logging output in a library function.
"TfOjG"
This looks like a secret.
We later found this string list to be very useful.
IDA Pro standard is the disassembler we used to conduct static analysis. After IDA Pro loaded the binary and finished its analysis, we opened up a 'functions' window and found out there were almost no meaningful names. Even though the binary is statically linked and stripped, IDA Pro computed very useful cross referencing information and was capable of identifying many Linux system calls as shown below,
Given such information, we identified many system call wrappers.
One may want to play with the interesting constant strings now. Doing a "sequence of byte" search (alt-b) for the string "resolv+: search order not specified or unrecognized keyword, host resolution will fail.", IDA Pro would jump to
Now one can jump to its cross references (ctrl-x). Since only one location is shown in the cross-reference window, one can type 'Enter' key to jump to it directly. IDA Pro would jump to a location like,
.text:0804AD37 push offset aResolvSearchOr ; "resolv+: search order not specified or "... .text:0804AD3C push 0Fh .text:0804AD3E push 0Bh .text:0804AD40 mov ecx, dword_8078F9C .text:0804AD46 push ecx .text:0804AD47 call sub_805E584
We see that the string is indeed used in a function (the status bar of IDA Pro tells us that the cursor in now in sub_804A9D8), and one can see that it is obviously being used as the fourth argument of a function call to sub_805E584. Now the problem is how to determine the original names of these functions.
Library function identification is a process to identify well-known library functions in a binary executable that doesn't contain symbol information. It can be done manually and/or automatically with tools. It's worth noting that there are simple binary rewriting techniques to defeat function identification tools based on byte-sequence signatures (fingerprints). A more advanced technique would be based on algorithm signatures.
For many executable formats, IDA Pro can identify statically linked functions with its FLIRT technology. Unfortunately, it doesn't have a signature database for libc. Without knowing Michal Zalewski's function fingerprint database for libc5 at first, we began our manual lib function identification process just to get the fun started. We found a copy of the source code of libresov+ by searching for 'resolv+' using Google. After unpacking the file, we built a project with our source code browser Source Insight. Then we searched the project for the string "resolv+: search order not specified or unrecognized keyword, host resolution will fail.", Source Insight returns one result in the file "Gethstnmad.c" in its search result window. By following its link to jump to the editor window, one can see in its symbol window that the string is being used in function "init_services". Now we're ready to give sub_804A9D8 a new name.
Open the "Relation Window" of Source Insight and put the cursor on the function name of "init_services" in the editor window. A call graph is quickly displayed as
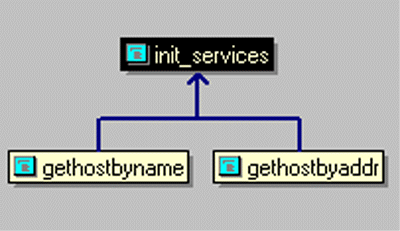
As can be seen here, "init_services" is called at two locations, one is "gethostbyname", and the other is "gethostbyaddr". Similarly, we can check out the callsites in "init_services", in the "relation window", right click on "init_services", the in the popup menu choose "View Relation"->"calls", then Source Insight displays
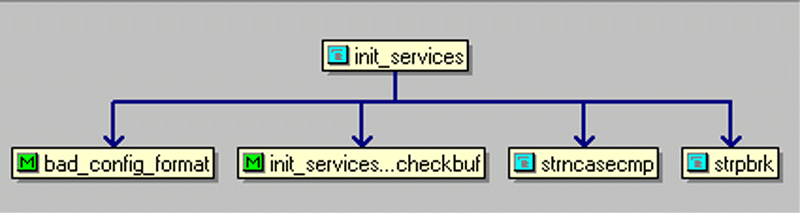
As you can see, "strncasecmp" and "strpbrk" are called. Unfortunately, some function names defined as macro constants were omitted.
Now, let's switch to IDA Pro, put the cursor on "sub_804A9d8" and right click (or type 'n' directly) to rename it to "init_services", then choose menu "View"->"Open subviews" ->"Function Calls". IDA Pro displays a window of "Callers and callees",

It tells us that "init_services" is called at three locations. Two of them don't have names, which is an indication that their entry addresses are not directly referenced anywhere in the binary. And the function has tens of callsites. Maybe in PDA Pro's future releases, the duplicated names can be eliminated.
It looks like the source code we used is old. We later downloaded the source code of libc 5.3.12, which includes the source code of resolv+. This time, the call graph in Source Insight is very close to the one in IDA Pro,

Given this type of information, one can manually recover many library function names in a stripped binary executable. But this is obviously a tedious process. One probably doesn't want to do this for hundreds of functions. It would be useful if a libc signature databasewere available for use in IDA Pro.
While reading Michal Zalewski's introduction to the tool, Fenris, he developed, we learned that he developed a tool to build fingerprint (signature) database and he built one for libc5 to demonstrate how to use Fenris with the binary of the Reverse Challenge. Note that his utility "dress" was not born yet then. Although Fenris is a dynamic analysis tool, we thought it might be possible to build an IDA Pro plug-in to use his signature database to identify library function names.
The first thing we did was to verify that we could pull out the piece of code that is responsible for building an in-memory structure of a fingerprint database from Fenris. Then we browsed the plug-in SDK of IDA Pro to see whether it supports the features we needed. At a minimum, we wanted to be able to enumerate functions, get instructions as bytes from a function, get the name of a function, and finally rename a function. Just as we expected, IDA Pro's SDK was well designed and supports everything we needed. Based on the "vcsamples" project shipped with the SDK, it took about 2 hours to get a working prototype which ignored the functions that we had already renamed manually (those that don't start with "sub_"). The next thing we did was to add a prompt for a user to ask for confirmation when duplicates names are encountered. After that was done, we ran the plug-in and were able to rename hundreds of functions. All of this was done before Michal Zalewski released his new utility "dress"; this bought us several days of time to move the work forward.
It's worth mentioning that the plug-in we developed couldn't recognize any functions in the "random" family by using his fingerprint database. One of the reasons is that the size of the fingerprint is defined as a fixed value of 24, while some wrapper functions are shorter than that. For example, if we take a look at the disassembly of rand,
.text:08056058 ; ¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦ S U B R O U T I N E ¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦ .text:08056058 .text:08056058 ; Attributes: bp-based frame .text:08056058 .text:08056058 rand proc near ; CODE XREF: main+28Bp .text:08056058 ; main+30Cp main+364p .text:08056058 ; main+388p ... .text:08056058 push ebp .text:08056059 mov ebp, esp .text:0805605B call rand_r .text:08056060 mov esp, ebp .text:08056062 pop ebp .text:08056063 retn .text:08056063 rand endp
It can be seen the routine is only 12 bytes long. Another reason is that Fenris is still in its beta status. Sometimes there is more than one signature for a certain function in its database, and sometimes there are several functions with the same signature. As far as I know, the FLIRT technology in IDA Pro uses variable length to resolve conflicts.
With many of the function names resolved, the next task was to manually resolve those remaining based on its context and our experience. An interesting thing to note is that some library calls are often used together in a certain order. If you see a certain library function is called, you may expect some other library function is also used close by. For example, if you see a call of "free", you may expect some function like "malloc" to be called somewhere earlier in the function or somewhere in the function's caller chain.
Let's take a look at an example to see how we can apply this type of knowledge. If one doesn't have the name of sub_80559A0 resolved already, checking its cross references reveals that it's being called twice in the "main" function by using the return value of the "time" call as its argument. Could it be "srand" being used to set the random seed? One can look at its assembly instructions and pay special attention to numerical constants and string constants.
.text:080559A0 push ebp .text:080559A1 mov ebp, esp .text:080559A3 push edi .text:080559A4 push esi .text:080559A5 push ebx .text:080559A6 mov edx, [ebp+arg_0] .text:080559A9 mov eax, dword_8078958 .text:080559AE mov [eax], edx .text:080559B0 cmp dword_807895C, 0 .text:080559B7 jz loc_8055BB0 .text:080559BD mov esi, 1 .text:080559C2 cmp dword_8078960, esi .text:080559C8 jle loc_8055B74 .text:080559CE mov edi, dword_8078958 .text:080559D4 mov eax, dword_8078960 .text:080559D9 dec eax .text:080559DA and eax, 3 .text:080559DD cmp dword_8078960, esi .text:080559E3 jle short loc_8055A5D .text:080559E5 test eax, eax .text:080559E7 jz loc_8055A9C .text:080559ED cmp eax, 1 .text:080559F0 jle short loc_8055A5D .text:080559F2 cmp eax, 2 .text:080559F5 jle short loc_8055A2C .text:080559F7 mov ecx, [edi+esi*4-4] .text:080559FB lea edx, [ecx+ecx*2] .text:080559FE shl edx, 8 .text:08055A01 add edx, ecx .text:08055A03 lea edx, [edx+edx*4] .text:08055A06 mov eax, edx .text:08055A08 shl eax, 0Ah .text:08055A0B add edx, eax .text:08055A0D lea edx, [ecx+edx*2] .text:08055A10 lea eax, ds:0[edx*8] .text:08055A17 sub eax, edx .text:08055A19 lea eax, [ecx+eax*4] .text:08055A1C lea eax, [eax+eax*4] .text:08055A1F add eax, 3039h .text:08055A24 mov [edi+4], eax .text:08055A27 mov esi, 2
Without going very far, one can find out that there is one, "3039h", at location 0x8055A1F. Do a search for "3039" in the libc source and get nothing. Then try again with its decimal equivalent "12345" and we have.
Destest.c (des): static char *f="0123456789ABCDEF";
Getopt.c (posix): c = getopt (argc, argv, "abc:d:0123456789");
Getopt1.c (posix): c = getopt_long (argc, argv, "abc:d:0123456789",
Iotempname.c (libio): "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Iotempname.c (libio): (12345ZZZ), NULL is returned. */
_itoa.c (libio):CONST char _itoa_lower_digits[] = "0123456789abcdefghijklmnopqrstuvwxyz";
_itoa.c (libio):CONST char _itoa_upper_digits[] = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
Mcprtlib.c (nls):intType: index = "0123456789abcdef";
Mcprtlib.c (nls): index = "0123456789ABCDEF";
Mkstemp.c (bsd): = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Mktemp.c (posix): = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
Pty.c (libbsd): for (cp2 = "0123456789abcdef"; *cp2; cp2++) {
__random.c (stdlib): state[i] = (1103515145 * state[i - 1]) + 12345;
__random.c (stdlib): state[0] = ((state[0] * 1103515245) + 12345) & LONG_MAX;
__random_r.c (stdlib): rand_data->state[i] = (1103515145 * rand_data->state[i - 1]) + 12345;
__random_r.c (stdlib): rand_data->state[0] = ((rand_data->state[0] * 1103515245) + 12345)
Vsprintf.c (elf\d-link): const char *digits="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
Vsprintf.c (elf\d-link): if (type&SMALL) digits="0123456789abcdefghijklmnopqrstuvwxyz";
So it's indeed used in "__random.c". You could either go further to compare the algorithms before drawing a conclusion, or you could just go ahead to rename it directly now with a question mark at the end of its name so that you can verify it later with other methods.
Type inference is a process to recover the data type of a certain memory region based on data flow analysis and known function signatures. The results of such a process are more meaningful names for global variables, local variables, and function parameters. One can even rename registers to make them more meaningful. Such a process is essential in that it's potentially possible to make a 'dead list' of disassembly as readable as C code. IDA Pro can perform type inference automatically if it has information for the relevant functions. With this ELF binary file, we were out of luck and had to do it manually. [Cigital work?]
One of the best places to start intra-procedure type inference is a sink node in the call graph of user-defined functions. The reason is obvious, one would be disturbed by other user-defined functions, and highly likely one would find variables passed to library functions. A natural way to do this is in a "bottom-up" fashion. Let's take a raw data sender routine at 0x08048F94 as an example. Close to the end of the routine, we have,
.text:080490ED push 10h .text:080490EF lea eax, [ebp+var_10] .text:080490F2 push eax .text:080490F3 push 0 .text:080490F5 mov eax, [ebp+arg_C] .text:080490F8 add eax, 16h .text:080490FB push eax .text:080490FC push esi .text:080490FD mov edi, [ebp+var_44] .text:08049100 push edi .text:08049101 call sendto .text:08049106 add esp, 18h .text:08049109 cmp eax, 0FFFFFFFFh .text:0804910C jnz short loc_8049118
Based on the function signature we found for "sendto",
int sendto (int sockfd, const void *buffer, size_t len,
unsigned flags, const struct sockaddr *to, int tolen);
One can infer that var_44 is being used as a socket file descriptor, so we expect it to be initialized somewhere at a previous location. Now put the cursor on "var_44", type "Enter" to bring up the "Stack Window", then type 'ctrl-x' to see its cross references. In the "xref" popup window, we can see it's modified at sub_8048F94+1A; hit "Enter" to jump there and the "xref" window goes away. The "Stack" window is still showing, press 'Esc" to let it go. Here is what we have in the disassembly window.
.text:08048FA0 push 0FFh .text:08048FA5 push 3 .text:08048FA7 push 2 .text:08048FA9 call socket .text:08048FAE mov [ebp+var_44], eax
Yes, indeed. It is being used as a socket file descriptor, and a raw socket is being created. Now it's safe to rename it to a more meaningful name. One can put the cursor on "var_44" and press 'n' (for renaming) key. In the popup dialog, type a new name "var_sock_fd" and hit "Enter", we have,
.text:08048FA0 push 0FFh .text:08048FA5 push 3 .text:08048FA7 push 2 .text:08048FA9 call socket .text:08048FAE mov [ebp+var_sock_fd], eax
Now, we want to return back to the "sendto" call site, press "Esc" to ask IDA Pro to "jump back" and IDA Pro would bring us to the original location,
.text:080490ED push 10h .text:080490EF lea eax, [ebp+var_10] .text:080490F2 push eax .text:080490F3 push 0 .text:080490F5 mov eax, [ebp+arg_C] .text:080490F8 add eax, 16h .text:080490FB push eax .text:080490FC push esi .text:080490FD mov edi, [ebp+var_sock_fd] .text:08049100 push edi .text:08049101 call sendto .text:08049106 add esp, 18h .text:08049109 cmp eax, 0FFFFFFFFh .text:0804910C jnz short loc_8049118
As you can see that the variable "var_44" is already displayed as "var_sock_fd" at location 0x80490FD. What a beautiful implementation of the Model-View-Controller (MVC) pattern.
Similarly we can infer that the esi register stores a pointer which points to a buffer of an IP datagram. Since var_sock_fd is a raw socket, the IP header should start at the offset 0 of the buffer. Because the sum of arg_C and 22 (0x16) is being used as the third argument 'len', we can infer the arg_C is related to the length of some buffer, so we can rename it to "arg_length". We are also ready to rename 'var_10' to 'var_sockaddr'. After inferring all the arguments, we can add a comment to make it easier to read,
.text:080490ED push 10h .text:080490EF lea eax, [ebp+var_sockaddr] .text:080490F2 push eax .text:080490F3 push 0 .text:080490F5 mov eax, [ebp+arg_data_length] .text:080490F8 add eax, 16h .text:080490FB push eax .text:080490FC push esi_heap_ip_hdr .text:080490FD mov edi, dword ptr [ebp+var_socket_fd] .text:08049100 push edi .text:08049101 call sendto ; sendto(var_sock_fd, esi_heap_ip_hdr, arg_length + 22, 0,var_sockaddr, 16);
After one has inferred the types of all the parameters of a function, the next natural step is to go to each call site of the function, and apply the knowledge of its parameters to the variables used as arguments. Since this is a very straightforward process, we'd like to skip the details.
Although one may argue that the example shown here is actually another type of function identification, I feel it deserves its own place. Even after library function identification and type inference are done, a certain block of disassembly may remain difficult to read. We will still use the routine at 0x08048F94 as an example, at location 0x8049094. We have:
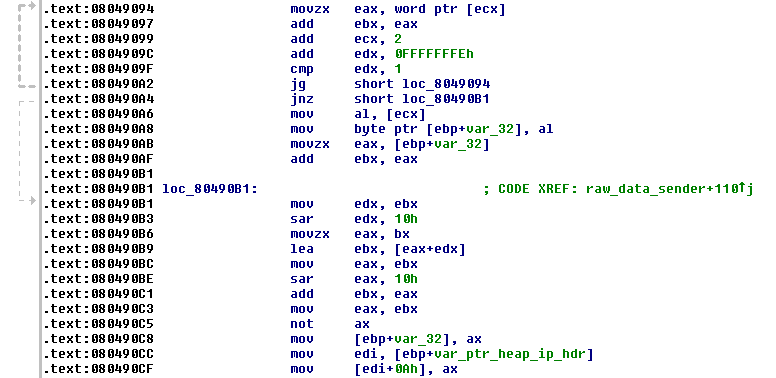
For such a block, one would like to add a comment to indicate what it does. At the very bottom, one can see that a word in the ax register is being stored at the byte offset 10 of a heap allocated IP header. The offset is for the field of IP header checksum. Instead of trying to figure out the functionality for the block form 0x8049094 to 0x80490C5, one can try to find a publicly available example of a checksum routine. Here is one we found in W. Richard Stevens' samples,
unsigned short
in_cksum(unsigned short *addr, int len)
{
int nleft = len;
int sum = 0;
unsigned short *w = addr;
unsigned short answer = 0;
/*
* Our algorithm is simple, using a 32 bit accumulator (sum), we add
* sequential 16 bit words to it, and at the end, fold back all the
* carry bits from the top 16 bits into the lower 16 bits.
*/
while (nleft > 1) {
sum += *w++;
nleft -= 2;
}
/* 4mop up an odd byte, if necessary */
if (nleft == 1) {
*(unsigned char *)(&answer) = *(unsigned char *)w ;
sum += answer;
}
/* 4add back carry outs from top 16 bits to low 16 bits */
sum = (sum >> 16) + (sum & 0xffff); /* add hi 16 to low 16 */
sum += (sum >> 16); /* add carry */
answer = ~sum; /* truncate to 16 bits */
return(answer);
}
As can be seen, it is basically a loop followed by a conditional branch. The pattern is exactly what the arrows provided by IDA Pro are telling us. So it's safe to conclude that the block is an in-lined version of a checksum routine. As one can imagine, the pattern may be present in other user-defined routines as well. Whenever a pattern of loop, conditional jump, and "not ax" is seen later, one can readily comment it as an in-lined checksum routine. It would be nice if IDA Pro allows a user to fold a block and give it a name. Here is what we have after this analysis,

By the way, the in-lined instructions generated by GCC for optimization contain an instruction that should be eliminated.
After the conclusions are drawn from the phase of static analysis, it is necessary to verify their correctness and completeness. One way to achieve this is to execute the target executable in a controlled environment. This is similar to blackbox testing. The testing requirements can be derived from the analysis conclusions. Testing input can be provided by different methods. Testing output can be made observable by using different tools and techniques.
Our testing environment is a VMware virtual local area network, which consists of two RH Linux 7.2 workstations, and one Windows NT 4.0 SP 6.0a workstation. Ddd is used as the front-end for gdb to perform debugging tasks; we found ddd helpful for observing memory blocks. Ethereal was used to examine network packets, and the reason again is that it's simple to use.
Observing the runtime behaviors of a target binary can be achieved in different ways. Sometimes, an analyst needs to verify a conclusion drawn for a certain routine in a binary executable. This is very similar to blackbox unit testing. One way of doing this is to patch the code at the entry point to make it call the target function with desired parameters. Another way is to run the target under a debugger and set a breakpoint at the entry point so that the registers and memory can be modified by debugger commands in order to execute the target function.
One of the questions from the challenge is to identify the binary's network data encoding process. It turned out that the encoding and decoding routines of the binary are very easy to identify by their parameters and the locations of their callsites. The encoding routine is very easy to understand, while the decoding routine is not. One thing we want to know is whether the routines are using the same algorithm. So we wanted to be able to pass some data to the encoding routine, then pass the encoded result to the decoding routine to see whether our original data would be returned back. The way we chose to achieve this was to use IDA Pro's "Create ASM file" feature to dump the disassembled instructions into a file. We then used Visual C++ compiler's inline assembler feature to test the encoding and decoding routines in program written in C. Here is the code listing:
#include#include char myC[] = "%c"; char aCS[] = "%c%s"; __declspec( naked ) void decode(unsigned int len, unsigned char *in, unsigned char *out){ __asm{ push ebp mov ebp, esp sub esp, 4 push edi push esi push ebx mov edi, [ebp+8] lea ebx, [edi-1] lea eax, [edi+3] and al, 0FCh sub esp, eax mov [ebp+(-4)], esp mov al, 0 mov esi, [ebp+10h] mov [esi], al test ebx, ebx jl do_exit loc_804A214: lea edx, [ebx-1] test ebx, ebx jz short loc_804A22C mov esi, [ebp+0Ch] movzx eax, byte ptr [ebx+esi] movzx edx, byte ptr [edx+esi] sub eax, edx jmp short loc_804A232 align 4 loc_804A22C: mov esi, [ebp+0Ch] movzx eax, byte ptr [esi] loc_804A232: lea ecx, [eax-17h] test ecx, ecx jge short loc_804A244 lea esi, [esi+0] loc_804A23C: add ecx, 100h js short loc_804A23C loc_804A244: xor edx, edx cmp edx, edi jge short loc_804A25D lea esi, [esi] loc_804A24C: mov esi, [ebp+10h] mov al, [edx+esi] mov esi, [ebp+(-4)] mov [edx+esi], al inc edx cmp edx, edi jl short loc_804A24C loc_804A25D: mov esi, [ebp+10h] mov [esi], cl mov edx, 1 cmp edx, edi jge short loc_804A27E nop loc_804A26C: mov esi, [ebp+(-4)] mov al, [edx+esi-1] mov esi, [ebp+10h] mov [edx+esi], al inc edx cmp edx, edi jl short loc_804A26C loc_804A27E: mov esi, [ebp+(-4)] push esi push ecx push offset aCS ; mov esi, [ebp+10h] push esi call sprintf add esp, 10h dec ebx ; jns loc_804A214 test ebx, ebx jge loc_804A214 do_exit: lea esp, [ebp+(-10h)] pop ebx pop esi pop edi mov esp, ebp pop ebp retn } } __declspec( naked ) void encode(unsigned int len, unsigned char *in, unsigned char *out){ __asm { push ebp mov ebp, esp push edi push esi push ebx mov edi, [ebp+8] mov esi, [ebp+0Ch] mov ebx, [ebp+10h] mov al, 0 mov [ebx], al mov al, [esi] add al, 17h movsx eax, al push eax push offset myC ; "%c" push ebx call sprintf mov ecx, 1 cmp ecx, edi jz short loc_804A1DD nop loc_804A1C8: movzx edx, byte ptr [ebx+ecx-1] movzx eax, byte ptr [ecx+esi] lea eax, [edx+eax+17h] mov [ecx+ebx], al inc ecx cmp ecx, edi jnz short loc_804A1C8 loc_804A1DD: lea esp, [ebp - 0Ch] pop ebx pop esi pop edi mov esp, ebp pop ebp retn } } void main() { char in[64], out[64]; strcpy(in, "IDA Pro rocks."); encode(64, (unsigned char *)in, (unsigned char *)out); decode(64, (unsigned char *)out, (unsigned char *)in); printf("%s\n", in); }
After executing the program, the string "IDA Pro rocks." was printed out as expected. The whole process took about twenty minutes, including resolving a Microsoft inline assembler bug. If you have read through our code listing carefully, you may have found out that there is a commented out line of "; jns loc_804A214 ". Somehow, the assembler couldn't generate a correct machine instruction for it. With the line included, it generated:
85: loc_804A27E: 86: mov esi, [ebp+(-4)] 004010C1 8B 75 FC mov esi,dword ptr [ebp-4] 87: push esi 004010C4 56 push esi 88: push ecx 004010C5 51 push ecx 89: push offset aCS ; 004010C6 68 34 2A 42 00 push offset aCS (00422a34) 90: mov esi, [ebp+10h] 004010CB 8B 75 10 mov esi,dword ptr [ebp+10h] 91: push esi 004010CE 56 push esi 92: call sprintf 004010CF E8 4C 02 00 00 call sprintf (00401320) 93: add esp, 10h 004010D4 83 C4 10 add esp,10h 94: dec ebx 004010D7 4B dec ebx 95: jns loc_804A214 004010D8 79 7E jns loc_804A1C8+8 (00401158) 96: ; test ebx, ebx 97: ; jge loc_804A214
Did you see that it's jumping forward while it should jump backward? :)
Oddly enough, we did perform blackbox unit testing of a Linux executable on a Windows NT 4.0 workstation by using Microsoft Visual C++. We then coded our encoding and decoding routines in C, and tested them by mixing them with the disassembled routines.
One of the conclusions of our static analysis is that the binary is a DDoS tool that can carry out different styles of packet flood attacks. We also established some understanding of its application protocol. In order to verify that this conclusion is actually correct, we wanted to be able to send a command to it to instruct it to start a certain type of flood attack. We initially focused on those that take few parameters so that we could easily verify our understanding of its protocol. The ones we chose were "Query Status", which takes just one control code as input, and "Init Remote IP", which must be invoked before invoking the "Query Status" command. As you may know, the source IP addresses field in the IP headers that an intruder sends is always spoofed.
So the first command we wanted to exercise is "Init Remote IP". Given the fact that the result of this command is in memory, the tool we need to verify the correct output is a debugger. We first wrote a simple program and made sure that it actually could send raw socket correctly to the running daemon. Here are the steps we took to verify it,
After making sure we could talk to the daemon, we felt we were ready to drop our previously developed encoding routine in the simple client and set the IP address according to its application protocol. We knew from our static analysis that the daemon supports three options for this command. The options are:
The first one is the simplest and it was the one we wanted to try first. We would use ddd this time so that we can examine the daemon's memory easily. The steps are,
We then tested the other two options and verified that the client IP address was stored as expected. Finally, we detached the debugger. As you can see, using a debugger allows us to improve the testability by augmenting the daemon's observable output space.
Since the "Query Status" command will send a reply to the client, we added our decoding routine and some other code for receiving raw sockets. The way that our client program worked was to issue an "Init IP Address" command first and then issue a "Query Status" command. We invoked the client and verified that we received an expected reply.
Another command with client-side output is "Remote Command". With some copy and paste, we modified our simple client program to issue an "ls -l" command. After invoking it, it was readily able to print out the daemon's reply in a very unprofessional manner. The output format was later beautified.
With some simple modifications, we were able to test other daemon's commands that interact with the system. At this stage, we added a simple interactive command line interface to our client program to make the testing easier. Here is how we tested some of them.
By adding some extra code in our client program, we were able to carry out some attacks. We brought up an instance of Ethereal on the victim machine, and then sent different flood commands to the daemon, trying to learn more about each type of attack by examining the outgoing packets. We actually started a Windows NT 4.0 workstation in VMware, and used it as a target to test the ICMP IP fragmentation attack and UDP IP fragmentation attack. As you can imagine, our NT workstation's CPU usage quickly went to 100% since it's running in an emulator. Unfortunately, we couldn't test the power of the Fraggle style attack in our virtual LAN environment. The NT workstation handled the TCP SYN flood attack well.
With some enhancements to our client, we were able to invoke all 12 commands supported by the daemon and generate packets logs to verify our conclusions. As you can see, dynamic analysis is helpful not only for verifying the conclusions drawn in the static analysis phase, but also for discovering new features that were not revealed in the static analysis phase. Because of the nature of some features, it's possible for one to draw conclusions faster by applying dynamic analysis than by applying static analysis.
Our greetz and shoutz go to Ilfak Guilfanov, Michal Zalewski and all others whose tools make the world a better place.